Monitoring Stock Prices with Prometheus and Molescrape
If you’re only trading stocks occassionally and not on a daily basis, you have the problem that you won’t check the prices regularly. This means that you might miss a price target at which you wanted to sell your stocks. Typically, stock brokers allow you to set Stop Loss to prevent too high losses, but to my knowledge at least my broker does not have monitoring capabilities to inform me when a stock price has risen upwards to a specific target (e.g. the break-even point to actually earn some money if I consider taxes and fees).
I recently bought stocks from an IT company in the believe that they will rise over time. Once they have reached my target value I might sell them or set a Stop Loss to secure earnings and wait for further improvements in the value. With my broker’s standard tools this does not seem to be possible.
Thus, I implemented my own monitoring with Prometheus and Molescrape (Disclaimer: Molescrape is developed by me). To visualize the prices and to set the alert ranges I use Grafana, but alerting is also possible in Prometheus directly.
Let’s see how we can develop our own stock price monitoring tool. I will not cover setup of neither Prometheus nor Molescrape in this tutorial. However, both run as services. For Prometheus you will need Prometheus and the Prometheus Pushgateway and for Molescrape you will need Molescrape Skyscraper and Molescrape Calkx.
Scraping the stock prices
First of all we have to scrape the stock prices from any website. Since I do not need much intraday data, I can take a very slow approach here and scrape the data once every two hours. Plus, I only scrape the stock prices I am actually interested in (i.e. stocks I hold or stocks I might want to buy in the near future). With this approach I should be fully compliant to the Directive 96/9/EC of the European Union regarding sui generis database rights, because I only scrape an extremely limited amount of the full database.
German jurisdiction also says that Terms of Use cannot restrict bots from crawling publicly accessible data. If you want to enforce your Terms of Use against web bots, you have to setup a login area and only display the data after login. Only with a login page you can legally ensure that a bot (or the owner of the bot) actually has to read your Terms of Use.
Now, let’s see how we can technically implement the data collection. With
Molescrape Skyscraper we implement a standard scrapy spider that emits a
BasicItem with an id field. This id field
will be used to remove duplicate messages, e.g. because the stock price
was not updated during two crawls (happens on weekends). In a configuration
file we can tell Skyscraper how often a specific spider should run and
Skyscraper will automatically schedule it for us in that interval. In this case
we want this to be two hours.
Since we all know that some companies go into law suits very quickly and I am not
willing to fight a law suit over a blog post (even though according to existing court
rulings I should win), I will not
provide code for any specific website. However, with some simple scrapy
knowledge you can quickly fill the gaps. A simple spider that extracts the
stock value of SAP could then look like this
(monitorexchange/stockexample.py):
import scrapy
from datetime import datetime
from skyscraper.items import BasicItem
class StockexampleSpider(scrapy.Spider):
name = 'stockexample'
allowed_domains = ['example.com']
start_urls = [
# Add all URLs you want to follow here, e.g.
'http://example.com/SAP-DE0007164600',
]
def parse(self, response):
isin = response.css('#ExampleComsStockIsin').extract_first()
# Many websites display important information in tables
share_table = response.css('#ExampleComsStockPriceTable')
price_currency = self._search_table(share_table, 'Value')
# Intentionally expect two values: if more fail with exception
price, currency = price_currency.split(' ')
update_time = self._search_table(share_table, 'Last Update')
parsed_time = datetime.strptime(update_time, '%Y-%m-%d %H:%M:%S')
item = BasicItem()
# This ID will be used to prevent duplicate storage of the same item
# For this use case we use a combination of the ISIN and the last
# update time, because we only need to store information when it was
# actually updated
item['id'] = '{}-{}'.format(isin, update_time)
item['url'] = response.url
item['data'] = {
'isin': isin,
'price': price,
'currency': currency,
'time': parsed_time.strftime('%Y-%m-%dT%H:%M:%S+0200'),
}
return item
def _search_table(self, table_rows, definition):
for row in table_rows:
try:
name, value = row.css('td::text').extract()
except ValueError:
# not 2 elements
continue
name = name.strip()
value = value.strip()
if name == definition:
return value
return None
To schedule this spider every two hours we add a file called
monitorexchange/stockexample.yml:
recurrence_minutes: 120
enabled: true
If we push these two files to our spider repository Skyscraper will fetch them and execute the spider every two hours.
Push data to Prometheus
Next, we have to get the scraped data into Prometheus. We can do this with Molescrape Calkx, the post processing framework of Molescrape. With Calkx we can read the scraped data and run any kind of calculation on it. In our case we will send the data to the Prometheus Pushgateway. Calkx will process a scraped item as soon as it is written to the hard disk by Skyscraper.
So, let’s create a Calkx job that reads scraped stock prices and sends them
to Prometheus. A Calkx job is a subclass of calkx.jobs.Job and has to
implement the method signature process_item(self, item). That’s it.
import calkx.jobs
from prometheus_client import CollectorRegistry, Gauge, push_to_gateway
class PrometheusJob(calkx.jobs.Job):
def __init__(self):
self.registry = CollectorRegistry()
self.g = Gauge('monitorexchange_stock_price',
'The Stock Price of a Share',
['isin', 'currency'],
registry=self.registry)
def process_item(self, item):
self.g.labels(isin=item['data']['isin'],
currency=item['data']['currency']) \
.set(item['data']['price'])
push_to_gateway('localhost:9091', job='monitorexchange',
registry=self.registry)
During instantiation of the class we setup prometheus_client and whenever we
see a new item we push its data to the Prometheus Pushgateway.
We can enable this job by defining an accompanying YAML configuration file for
it. For this, we store the Python code into a directory with the project
name (monitorexchange in my case) and create a yml file with the same
name:
|
+- monitorexchange/
|
+- prometheus.py
+- prometheus.yml
To connect the Calkx job to our spider we have to define the spider’s name
in the YAML configuration file. The project name will automatically be
read from the folder name. Since our Calkx job requires the prometheus_client
package in Python, we will also define this in the configuration will (and
Calkx will then automatically install it for us):
enabled: true
spiders:
- stockexample
requires_packages:
- prometheus_client
Visualize and define alert rules
We can now find the stock prices as metric monitorexchange_stock_price in
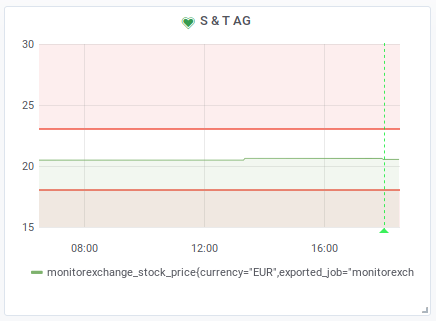
Prometheus and Grafana. With a simple filter like
monitorexchange_stock_price{isin="DE0007164600"} you can plot them as
a chart and define Grafana alerts. For example, I like to set alerts for when
a metric goes outside of range to get a mail both if the stock price is too
low (I might have to sell it to avoid losses) or if the stock price is
high (I might want to think about selling it or at least want to define a
Stop Loss to be sure to sell it in the winning zone).
For example here is a screenshot from an alert for an Austrian IT company that among other services also offers SAP services.