Gaussian-Mixture-Model in R
In meinem letzten Eintrag zum Kaggle-Wettbewerb zur Fahrradnutzung habe ich zwei Verteilungen der Uhrzeiten geplottet, zu welchen Fahrräder gemietet wurden. In einer davon waren zwei Spitzen zu erkennen und grob sieht es auch nach zwei Gaussglocken aus.
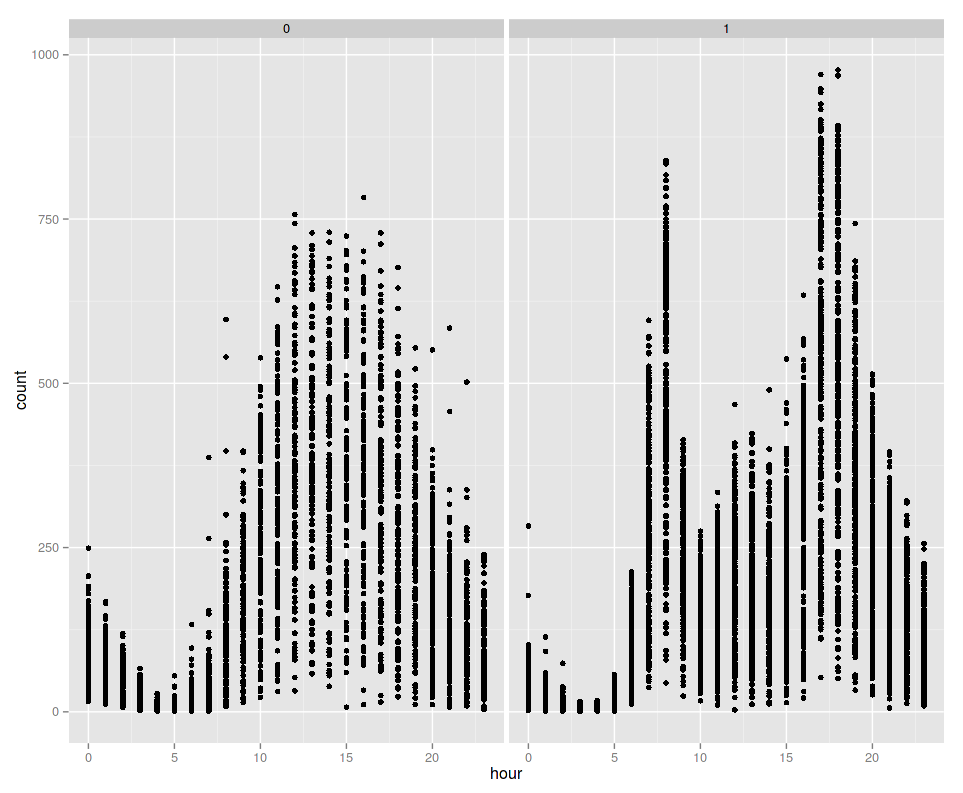
In so einem Fall kann man versuchen, ob man mit einem Gaussian-Mixture-Model weiterkommt. Das ist ein Model, bei dem zwei Gaussverteilungen so kombiniert werden, dass man eine neue Wahrscheinlichkeitsverteilung erhält.
Hierzu müssen wir die Daten in R zunächst einmal so umwandeln, dass sie eindimensional sind und jeder Wert mit der korrekten Häufigkeit auftritt. Hatten wir bisher gespeichert, dass um 7 Uhr X Fahrräder und um 8 Uhr Y Fahrräder geliehen wurden, so muss nun die Uhrzeit 7 Uhr X-mal auftreten und die Uhrzeit 8 Uhr Y-mal. Mit so einer Verteilungsliste kann man dann Funktionen für Gaussverteilungen füllen.
Praktischerweise benötigt man in R mit rep hierfür nach dem Laden der Daten nur eine Zeile.
t = read.csv('train_altered.csv', header=TRUE)
hours = rep(t$hours, times=t$count)Hiermit wird jede Uhrzeit entsprechend der Anzahl an gemieteten Fahrrädern mehrfach in einem Vektor gespeichert.
Mit dem Paket mixtools kann man dann ein Gaussian-Mixture-Model berechnen:
library(mixtools)
model = normalmixEM(hours)
plot(model, which=2)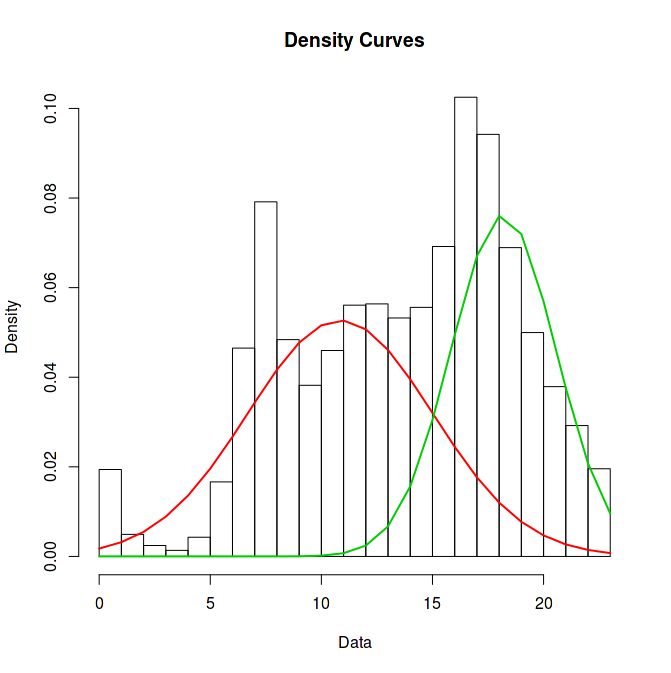
Leider ist zu erkennen, dass die Gaussverteilungen nicht zu den Höhepunkten passen. Das liegt daran, dass nach rechts hin aus dem Bild heraus Messwerte fehlen, die die grüne Gausskurve “auffüllen” könnten. Deshalb ist die grüne Gausskurve viel zu klein und die rote muss nach rechts rutschen, um den Fehler in der Mitte des Plots zu kompensieren.
Allerdings kann man erkennen, dass man sehr viel flachere Randstücke erreichen kann, wenn man das Histogramm ein wenig rotiert. D.h. 4 Uhr soll ganz nach links an den Rand des Plots und niedrigere Uhrzeiten dafür ganz nach rechts. Dann wären beide Ränder flach und ein Gaussmodell würde besser passen.
Auch das lässt sich in R schnell umsetzen.
hours_moved = (hours-4) %% 24Und hiermit kann erneut ein Modell trainiert werden, das wesentlich besser auf die tatsächliche Verteilung passt.
model = normalmixEM(hours_moved)
plot(model, which=2)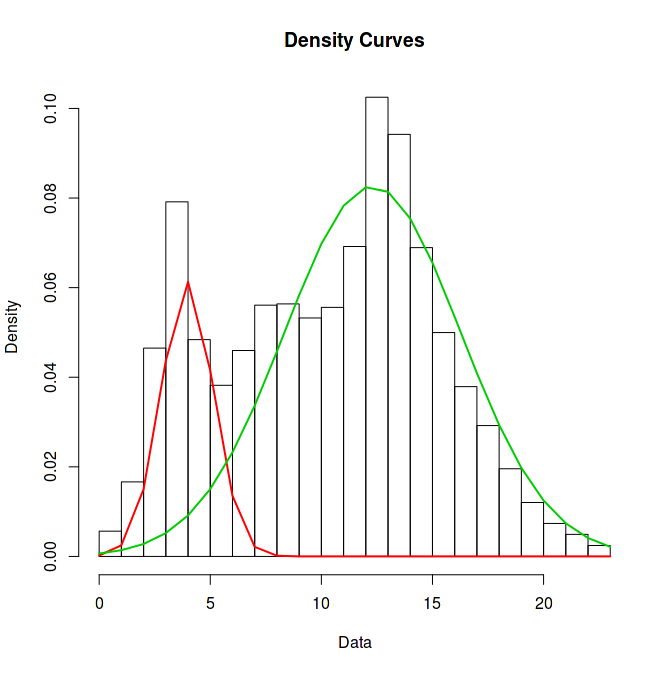
Anmerkung: Ich sehe im Moment nur noch nicht, ob mich das GMM beim Kaggle-Wettbewerb weiterbringen kann oder nicht. Ich kann jetzt ja erstmal nur sagen, mit welcher Wahrscheinlichkeit zu welcher Uhrzeit ein Fahrrad gemietet wird (an Werktagen wohlgemerkt). Bei Kaggle muss ich jedoch die Anzahl an Fahrradvermietungen vorhersagen. Trotzdem ist es natürlich gut, GMMs mal ausprobiert zu haben und auch gesehen zu haben, welchen Effekt eine Achsenverschiebung hier haben kann.
Zur Referenz noch dieselbe Lösung in Python mit Numpy und Scikit-Learn:
import pandas as pd
import numpy as np
from sklearn import mixture
df = pd.read_csv('train_altered.csv', index_col=0, parse_dates=[0])
hours = np.repeat(df['hour'].values, df['count'].values)
hours_moved = (hours - 4) % 24
np.random.seed(1)
g = mixture.GMM(n_components=2)
g.fit(hours_moved)
print(g)
print(np.round(g.means_, 2))