Disco: Eine Alternative zu Hadoop
Die Administration von Hadoop ist für einen Hobby-Nutzer relativ umständlich. Nach dem, was ich im Berufsleben bisher von Hadoop gesehen habe, hatte ich zumindest keine Lust, mir zu Hause ein Testsystem einzurichten, das über eine fertige Distribution hinausgeht.
Umso interessanter erschien mir das Projekt Disco, als ich davon gelesen habe. Es ist ebenfalls eine Plattform zur parallelen Verarbeitung großer Datenmengen (ebenfalls mit verteiltem Dateisystem und Map-Reduce). Allerdings wurde es in Erlang programmiert, setzt für die Map-Reduce-Scripts nativ auf Python und wirkt auch sonst von der Dokumentation näher an meiner privaten Linux-Umgebung. Außerdem soll es wesentlich einfacher einzurichten sein.
Test einer lokalen Instanz
Beim Test auf nur einer lokalen Instanz (Archlinux) zeigten sich die ersten Schwierigkeiten. Die aktuelle Version von Disco funktioniert nicht mit Erlang 18.2 (laut Pull Request #632 seit 18.1 nicht mehr). Zwar funktioniert der genannte Pull Request nicht mit früheren Versionen von Erlang (und wurde deshalb noch nicht übernommen), mit den neueren jedoch schon.
Wenn man auf einem normalen Produktivsystem testet, kann man den Befehl
make install einfach weglassen und für die Python-Scripts virtualenv
verwenden, um die Dateien nicht irgendwo im System zu verteilen.
PWD="`pwd`"
mkdir disco_test
DISCO_HOME=$PWD/disco_test
cd $DISCO_HOME
git clone https://github.com/discoproject/disco.git
# depending on Erlang version https://github.com/ysz/disco.git
cd disco
make
virtualenv env
source env/bin/activate
cd lib && python setup.py install && cd ..
bin/disco startDa Disco über SSH kommuniziert (auch mit dem localhost), müssen wir noch SSH-Keys einrichten und akzeptieren.
ssh-keygen -N '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh localhostDer letzte Schritt ist dazu da, einmal den Fingerprint zu bestätigen.
Alternativ könnte man auch StrictHostKeyChecking=no setzen.
Standardmäßig ist der Master (den wir eben installiert haben) mit einem Worker eingerichtet, sodass wir direkt einen Job starten können.
Ein einfaches Beispielskript für den ersten Test liefert das Disco-Tutorial:
from disco.core import Job, result_iterator
def map(line, params):
for word in line.split():
yield word, 1
def reduce(iter, params):
from disco.util import kvgroup
for word, counts in kvgroup(sorted(iter)):
yield word, sum(counts)
if __name__ == '__main__':
job = Job().run(input=["http://discoproject.org/media/text/chekhov.txt"],
map=map,
reduce=reduce)
for word, count in result_iterator(job.wait(show=True)):
print(word, count)Hier wird die Anzahl an Vorkommnissen pro Wort in einem Text gezählt, wobei der Text von einem HTTP-URL heruntergeladen wird.
Einen Cluster unter Amazon EC2 einrichten
Hat man einen AWS-Account, kann man sich halbwegs leicht einen Test-Cluster einrichten. Die Dokumentation zur Einrichtung eines richtigen Clusters fand ich teilweise etwas zerstreut, aber mit ein wenig Recherche kommt man dann doch durch.
Zunächst einmal muss man wissen, dass man Master-Instanzen und
Node-Instanzen installieren kann. Wobei die Master-Instanz eine Übermenge
der Node-Instanz ist. Das heißt, man kann theoretisch überall den Master
installieren, hat dann aber unnötig viel installiert.
Der Unterschied liegt lediglich in der Zeile make install für den Master
gegen make install-node für den Node.
Außerdem funktionierte bei mir Disco nicht unter der Amazon AMI
(ami-60b6c60a), sondern nur mit Ubuntu Server 14.04 (ami-fce3c696). Das
habe ich als zweites ausprobiert, als ich gesehen habe, dass das offizielle
AWS-Setup-Script Ubuntu verwendet. Ansonsten hätte ich
vermutlich vorher noch RHEL probiert, weil ich Ubuntu als Serversystem
meide.
Vorbereitung der EC2-Umgebung
Als allererstes richten wir uns eine neue Security Group für unsere EC2-Instanzen ein. Ich habe zwei relevante Security Groups aktiv:
- Disco:
- Inbound: All traffic, All protocols, All ports,
[ID der Security Group selbst] - Outbound: All traffic, All protocols, All ports,
0.0.0.0/0
- Inbound: All traffic, All protocols, All ports,
- SSH everywhere:
- Inbound: SSH, TCP, 22,
0.0.0.0/0 - Outbound: All traffic, All protocols, All ports,
0.0.0.0/0
- Inbound: SSH, TCP, 22,
Den SSH-Zugang kann man sich natürlich auch auf “My IP” stellen, mit einer dynamischen IP ist das allerdings lästig, da dann jeden Tag die Gruppe aktualisiert werden muss.
Die Security Group Disco dient allen Disco-Knoten zur Kommunikation untereinander. Jeder, der in dieser Gruppe ist, darf zu jedem anderen in der Gruppe auf allen Ports kommunizieren. SSH everywhere dient denjenigen Knoten, auf die wir während der Installation zugreifen müssen.
Installation des Masters
Fangen wir mit dem Master an. Als allererstes richten wir wieder die SSH-Keys ein.
ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
sudo sh -c "echo 'StrictHostKeyChecking no' >> /etc/ssh/ssh_config"Jetzt müssen wir uns noch ein Erlang-Cookie einrichten, das anscheinend zur Authentifizierung von [verteiltem Erlang-Code][distributed-erlang] selbst verwendet wird.
Authentication determines which nodes are allowed to communicate with each other. In a network of different Erlang nodes, it is built into the system at the lowest possible level. Each node has its own magic cookie, which is an Erlang atom.
When a node tries to connect to another node, the magic cookies are compared. If they do not match, the connected node rejects the connection.
Das Erlang-Cookie muss auf allen unseren Disco-Knoten denselben Inhalt haben. Den Zufallsgenerator habe ich von earthgecko.
SECRET_COOKIE=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 32 | head -n 1)
echo $SECRET_COOKIE >> cookie
mv cookie .erlang.cookie
chmod 400 .erlang.cookieAnschließend können wir die Pakete aus dem Repository installieren und Disco kompilieren und installieren:
sudo apt-get update
sudo apt-get -y install erlang git make
git clone https://github.com/discoproject/disco
cd disco
git checkout origin/master
make
sudo make install
cd lib && sudo python setup.py install && cd ..
sudo chown -R $USER /usr/var/discoInstallation der Slaves (Nodes)
Die Installation der Slaves läuft sehr ähnlich zum Master ab, bis auf die
Zeile sudo make install-node. Zusätzlich brauchen wir bei den Slaves
noch einige bekannte Werte vom Master, nämlich das Erlang-Cookie und auch
den SSH-Public-Key. Außerdem müssen wir unseren SSH-Public-Key vom Slave
dann auch noch an den Master senden.
Da Master und Slave bisher in keiner Richtung miteinander kommunizieren können, müssen wir den Public-Key des Masters auf unseren lokalen PC kopieren und dann auf den Slave laden.
scp ${AMI_USER}@${EC2_MASTER}:.ssh/id_rsa.pub ./master.pub
scp ./master.pub ${AMI_USER}@${EC2_SLAVE}:master.pub
ssh ${AMI_USER}@${EC2_SLAVE} 'cat ~/master.pub >> ~/.ssh/authorized_keys'Damit ist schonmal die Verbindung vom Master zum Slave möglich. Da wir sowieso
schon vom lokalen PC aus mit den beiden kommunizieren, können wir umgekehrt
genau denselben Weg gehen (alternativ wäre es nun auch möglich, vom Master
aus den Pubkey des Slaves via scp zu beziehen).
ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
sudo sh -c "echo 'StrictHostKeyChecking no' >> /etc/ssh/ssh_config"
scp ${AMI_USER}@${EC2_SLAVE}:.ssh/id_rsa.pub ./slave.pub
scp ./slave.pub ${AMI_USER}@${EC2_SLAVE}:slave.pub
ssh ${AMI_USER}@${EC2_MASTER} 'cat ~/slave.pub >> ~/.ssh/authorized_keys'Und das Erlang-Cookie müssen wir auch noch vom Master zum Slave kopieren:
scp ${AMI_USER}@${EC2_MASTER}:.erlang.cookie ./master.erlang.cookie
scp ./master.erlang.cookie ${AMI_USER}@${EC2_SLAVE}:.erlang.cookie
ssh ${AMI_USER}@${EC2_SLAVE} 'chmod 400 .erlang.cookie'Nachdem diese ganzen Kommunikationseinstellungen erledigt sind, können wir vom Slave aus endlich den Rest abarbeiten, der fast genau gleich wie beim Master läuft:
sudo apt-get update
sudo apt-get -y install erlang git make
git clone https://github.com/discoproject/disco
cd disco
git checkout origin/master
make
sudo make install-node
cd lib && sudo python setup.py install && cd ..
sudo chown -R $USER /usr/var/discoKonfiguration des Clusters
Da wir außer Port 22 keine weiteren Ports vom Internet aus zugelassen haben, müssen wir uns einen SSH-Tunnel aufsetzen, um die webbasierte Oberfläche von Disco zu erreichen. Diese ist notwendig, um den Cluster zu konfigurieren. Wenn man das Format der Cluster-Konfigurationsdatei kennt, kann man sie natürlich auch manuell schreiben, definiert ist es allerdings (meines Wissens) nicht.
Den SSH-Tunnel können wir so aufbauen:
ssh -N -p 22 ${AMI_USER}@${EC2_MASTER} -L 8989:localhost:8989Und anschließend erreicht man die Weboberfläche ganz normal über Aufruf
von http://localhost:8989 im Browser.
Automatisierung des Setups
Dieses ganze Setup kann man sich nun natürlich auch in Scripts automatisieren. Einen Ansatz hierzu gibt es bereits unter dem Namen disposabledisco. disposabledisco hebt sich meines Erachtens besonders durch die Verwendung von Spot-Instanzen hervor.
Neben dem bisher bereits entwickelten Code (in etwas abgewandelter Form) benötigen wir nun auch noch die SSH-Kommunikation, um die SSH-Schlüssel zwischen Master und Slaves zu verteilen. Außerdem müssen wir natürlich auch die Instanzen automatisiert anlegen.
Ich habe mich dazu entschieden, das Script in Python mit boto3 zu
programmieren. Als SSH-Bibliothek gibt es paramiko.
Vom Ablauf her starten wir zunächst einmal einen Master und danach die
gewünschte Anzahl von Slaves. Man kann dem Funktionsaufruf create_instances
direkt die Anzahl an zu startenden Servern mitgeben. Beim Aufruf von
create_instances geben wir auch gleich ein Startup-Script mit an, das
die Rechner nach dem Booten ausführen sollen, um alle notwendigen Dienste
einzurichten. Dies ist der schwierigste Teil, da sich das Startup-Script
meines Wissens nicht besonders gut debuggen lässt.
Beide Scripts sind relativ ähnlich, wobei der Master das .erlang.cookie
anlegt und der Slave dies erst später vom Master erhält. Außerdem wird
entsprechend der gewünschten Instanz das richtige make-Target install
oder install-node ausgeführt.
Zunächst das Script für den Master:
#!/bin/bash
DISCO_USER=disco
useradd -d /home/${DISCO_USER} -m -g users -s /bin/bash -p $RANDOM ${DISCO_USER}
echo "StrictHostKeyChecking no" >> /etc/ssh/ssh_config
apt-get update
apt-get -y install erlang git make
sudo -u $DISCO_USER bash << "EOF"
cd $HOME
ssh-keygen -t rsa -N '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
echo "ssh-rsa {PUBKEY} tempuser" >> $HOME/.ssh/authorized_keys
echo $RANDOM > $HOME/.erlang.cookie
chmod 400 $HOME/.erlang.cookie
git clone https://github.com/discoproject/disco
cd disco
git checkout origin/master
make
EOF
export HOME=/root # seems unset according to make install output
cd /home/${DISCO_USER}/disco
make install > /home/${DISCO_USER}/make-install 2>&1
cd lib && python setup.py install && cd ..
chown -R ${DISCO_USER} /usr/var/discoUnd das Script für den Slave:
#!/bin/bash
DISCO_USER=disco
useradd -d /home/${DISCO_USER} -m -g users -s /bin/bash -p $RANDOM ${DISCO_USER}
echo "StrictHostKeyChecking no" >> /etc/ssh/ssh_config
apt-get update
apt-get -y install erlang git make
sudo -u ${DISCO_USER} bash << "EOF"
cd $HOME
ssh-keygen -t rsa -N '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
echo "ssh-rsa {PUBKEY} tempuser" >> $HOME/.ssh/authorized_keys
git clone https://github.com/discoproject/disco
cd disco
git checkout origin/master
make
EOF
export HOME=/root # seems unset according to make install output
cd /home/${DISCO_USER}/disco
make install-node > /home/${DISCO_USER}/make-install-node 2>&1
cd lib && python setup.py install && cd ..
chown -R ${DISCO_USER} /usr/var/discoIn diesen Code-Segmenten ist jetzt noch der Platzhalter {PUBKEY} enthalten.
Zwar verwendet EC2 sowieso schon meinen Public-Key auf den Instanzen,
allerdings ist mein zugehöriger Private-Key passwortgeschützt und ich
möchte mein Passwort nicht in den Python-Code für paramiko eingeben. Deswegen
generiere ich ein temporäres Schlüsselpaar und lade den Public-Key davon in
die EC2-Instanz.
k = paramiko.RSAKey.generate(1024)
k.write_private_key_file(ssh_priv_file)
temp_pubkey = k.get_base64()
print("Temp SSH privkey is at %s" % ssh_priv_file)Das Hochfahren der Knoten ist dann relativ einfach. Wir starten zunächst den Master und dann die Slaves mit den Einstellungen wie zuvor auch. Eine kleine Stolperfalle gibt es nun noch. Bei mir im Cost Management schienen plötzlich Gebühren für regional traffic auf. Diese wurden vermutlich verursacht, weil meine Instanzen nicht in derselben Availability Zone waren. Deshalb müssen wir beim Starten der Slaves noch die Availability Zone angeben, in der auch der Master bereits läuft.
session = boto3.session.Session(profile_name='startinst')
client = session.client('ec2')
ec2 = session.resource('ec2')
# Startup master
master_script = ec2_helpers.read_user_data_file('init_scripts/disco_master.sh')
master_script = master_script.replace('{PUBKEY}', temp_pubkey)
instances = ec2.create_instances(MinCount=1,
MaxCount=1,
ImageId='ami-fce3c696',
KeyName=settings.key_name,
InstanceType='t2.micro',
SecurityGroupIds=['sg-70240009', 'sg-a9f4d0d0'],
InstanceInitiatedShutdownBehavior='terminate',
UserData=master_script)
instance_id = instances[0].instance_id
while not ec2_helpers.is_instance_running(instance_id, client):
time.sleep(30)
master_info = ec2_helpers.get_instance_info(instance_id, client)
master_az = master_info['Placement']['AvailabilityZone']
print("Disco master started at %s" % master_info['PublicDnsName'])
print("Master is in AZ %s" % master_az)
# Startup slaves
slave_script = ec2_helpers.read_user_data_file('init_scripts/disco_slave.sh')
slave_script = slave_script.replace('{PUBKEY}', temp_pubkey)
slave_instances = ec2.create_instances(MinCount=slave_count,
MaxCount=slave_count,
ImageId='ami-fce3c696',
Placement={'AvailabilityZone': master_az},
KeyName=settings.key_name,
InstanceType='t2.micro',
SecurityGroupIds=['sg-70240009', 'sg-a9f4d0d0'],
InstanceInitiatedShutdownBehavior='terminate',
UserData=slave_script)
# TODO: Apply required changes to a slave as soon as it is running, so that
# we get working slaves as quickly as possible
# TODO: Can be made more efficient by calling describe_instances one time
# with all instances and then iterating the return list
slave_ids = list(map(lambda inst: inst.instance_id, slave_instances))
while not all(map(lambda inst_id: \
ec2_helpers.is_instance_running(inst_id, client), slave_ids)):
time.sleep(30)
for slave_id in slave_ids:
inst_info = ec2_helpers.get_instance_info(slave_id, client)
print("Disco slave started at %s" % inst_info['PublicDnsName'])Wenn alle Instanzen
laufen, lassen wir uns über eine SSH-Verbindung den Public-Key vom Master
ausgeben und laden diesen auf die Slaves hoch. Genauso verfahren wir
umgekehrt: Wir geben die Public-Keys der Slaves aus und laden sie auf den
Master hoch. Außerdem holen wir uns das .erlang.cookie vom Master und
laden es ebenfalls auf die Slaves hoch. Dabei ist darauf zu achten, dass das
Cookie exakt die Rechte 400 (Eigentümer lesen) haben muss.
try:
master_ssh = ec2_helpers.connect_via_ssh_timeout(master_info['PublicDnsName'],
'disco', 10, ssh_priv_file)
def fetch_file(ssh_conn, server_filepath):
stdin, stdout, sterr = \
ssh_conn.exec_command('cat %s' % server_filepath)
content = ''.join(stdout.readlines())
return content
master_pubkey = fetch_file(master_ssh, '~/.ssh/id_rsa.pub')
master_erlcookie = fetch_file(master_ssh, '~/.erlang.cookie').strip()
slave_priv_dns = []
for slave_instance in slave_ids:
print(slave_instance)
inst_info = ec2_helpers.get_instance_info(slave_instance, client)
slave_ssh = ec2_helpers.connect_via_ssh_timeout(
inst_info['PublicDnsName'], 'disco', 10, ssh_priv_file)
slave_ssh.exec_command('echo "%s" >> ~/.ssh/authorized_keys'
% master_pubkey)
print('Uploaded master\'s SSH key to slave')
slave_ssh.exec_command('echo "%s" >> ~/.erlang.cookie'
% master_erlcookie)
slave_ssh.exec_command('chmod 400 ~/.erlang.cookie')
print('Uploaded master\'s Erlang cookie to slave')
slave_pubkey = fetch_file(slave_ssh, '~/.ssh/id_rsa.pub')
master_ssh.exec_command('echo "%s" >> ~/.ssh/authorized_keys'
% slave_pubkey)
slave_ssh.close()
print('Uploaded slave\'s SSH key to master')
slave_priv_dns.append(inst_info['PrivateDnsName'].replace('.ec2.internal', ''))
finally:
try:
if master_ssh:
master_ssh.close()
except NameError:
pass
try:
if slave_ssh:
slave_ssh.close()
except NameError:
passAußerdem haben wir uns an dieser Stelle auch gleich die Private-Hostnames
der Slaves gespeichert. Diese brauchen wir zur korrekten Einrichtung der
Disco-Konfiguration. Da leider nur vorgesehen ist, diese über die Weboberfläche
zu ändern, ist der Code hierzu entsprechend hässlich, da ich die
Struktur ohne viel Aufwand nachbauen und in die Datei schreiben wollte. Der
folgende Code-Block ist auch noch Teil des try-Blocks.
master_priv_dns = master_info['PrivateDnsName'].replace('.ec2.internal', '')
# Write config file manually, so that we do not need web interface
slave_conf = ','.join(['[\\"%s\\",\\"1\\"]' % dns for dns in slave_priv_dns])
master_ssh.exec_command('echo "{\\"hosts\\":[[\\"%s\\",\\"0\\"],%s],\\"blacklist\\":[\\"%s\\"],\\"gc_blacklist\\":[]}" > /usr/var/disco/disco_8989.config' % (master_priv_dns, slave_conf, master_priv_dns))
print('echo "{\\"hosts\\":[[\\"%s\\",\\"0\\"],%s],\\"blacklist\\":[\\"%s\\"],\\"gc_blacklist\\":[]}" > /usr/var/disco/disco_8989.config' % (master_priv_dns, slave_conf, master_priv_dns))
# now we can finally start disco (a restart is required after manual
# config change anyway
master_ssh.exec_command('disco start')
print('ssh -N -p 22 -i %s disco@%s -L 8989:localhost:8989' % (ssh_priv_file, master_info['PublicDnsName']))Anwendungsfall: Google n-grams
Als kleinen Anwendungsfall für Disco wollen wir die Google n-grams, genauer gesagt die 2-grams auswerten. Das wollen wir auch gleich dazu nutzen, Disco ein wenig zu evaluieren. Hierzu schreiben wir uns zunächst ein Script, das alle notwendigen Dateien von Google herunterlädt und entpackt. Dann versuchen wir einmal, die Daten bereits gechunkt (so wie sie von Google kommen) ins DDFS zu schreiben und einmal sie zusammenzufügen und dann ins DDFS zu schreiben und chunken zu lassen.
Dateien ins DDFS kopieren
Wichtig bevor wir Dateien ins DDFS kopieren: Sollte ein Rechner keine Worker
beheimaten (üblicherweise der Master), so muss man diesen anscheinend im DDFS
blacklisten. Andernfalls bleiben bei mir immer einige Map-Tasks im
Status waiting hängen und gehen nicht weiter. Sobald ich in diesem Fall dem
Master einen Worker zugesprochen habe, wurde sofort mit der Abarbeitung der
Tasks begonnen. Eventuell wäre die richtigere Einstellung auch Blacklisted
nodes for Disco, das habe ich mir noch nicht genau angesehen. Der
Beschreibung zufolge scheint Blacklisted nodes for DDFS ein Subset von
Blacklisted Nodes for Disco zu sein - zumindest dann, wenn noch keine
Daten im DDFS sind?
- Blacklisted nodes for Disco: No new disco tasks or ddfs blobs will be assigned to the node.
- Blacklisted nodes for DDFS: Re-replicates the blobs out of this node and prepares it for being removed from the cluster.
Hier das Script, das die Dateien herunterlädt und gleich zusammenfügt:
#!/bin/bash
touch googlebooks-ger-all-2gram-20090715.csv
for i in `seq 0 99`; do
wget http://storage.googleapis.com/books/ngrams/books/googlebooks-ger-all-2gram-20090715-${i}.csv.zip
unzip googlebooks-ger-all-2gram-20090715-${i}.csv.zip
cat googlebooks-ger-all-2gram-20090715-${i}.csv >> googlebooks-ger-all-2gram-20090715.csv
rm googlebooks-ger-all-2gram-20090715-${i}.csv
rm googlebooks-ger-all-2gram-20090715-${i}.csv.zip
doneDie entpackten und zusammengefügten Daten der Google 2-grams (für Deutsch in der Version von 2009) haben 49GB. Um diese nun ins DDFS zu kriegen und DDFS das Chunken übernehmen zu lassen, brauchen wir folgenden Befehl.
ddfs chunk data:2grams ./googlebooks-ger-all-2gram-20090715.csvDer Pfadbeginn ./ ist wichtig, da DDFS den Namen sonst für ein DDFS-Tag
hält und einen Fehler ausgibt.
Die Verarbeitung dauerte bei mir mit insgesamt fünf Maschinen (1 Master,
4 Slaves) auf t2.micro-Instanzen 95 Minuten (real), wobei 70 Minuten davon
wirklich gearbeitet wurde (user + sys)
real 94m53.527s
user 69m43.719s
sys 0m47.463sDaten verarbeiten
Diese Daten aus dem DDFS können wir nun relativ leicht parallelisiert verarbeiten lassen, indem wir das Beispielskript für Map-Reduce ein wenig anpassen, um die n-gram-Dateien zu parsen. Jede Zeile der n-gram-Daten enthält ein Wort, das Jahr, die Anzahl insgesamt, die Anzahl der Seiten, in denen das Wort auftritt, und die Anzahl der Bücher, in denen das Wort auftritt, in genannter Reihenfolge, separiert durch Tabs.
ngram TAB year TAB match_count TAB page_count TAB volume_count NEWLINE
Wenn wir den Mapper ein wenig anpassen, können wir schon die n-grams aufsummieren und uns so die 100 über alle Jahre hinweg häufigsten n-grams ausgeben lassen.
from disco.core import Job, result_iterator
import disco
import operator
import csv
def map(line, params):
parts = line.strip().split('\t')
if len(parts) != 5:
return
ngram = parts[0]
year = parts[1]
count = parts[2]
yield ngram, int(count)
def reduce(iter, params):
from disco.util import kvgroup
for word, counts in kvgroup(sorted(iter)):
yield word, sum(counts)
if __name__ == '__main__':
job = Job().run(input=["tag://data:2grams"],
map=map,
reduce=reduce,
map_reader = disco.worker.task_io.chain_reader)
with open('/home/disco/out.csv', 'w') as fp:
writer = csv.writer(fp)
for word, count in sorted(result_iterator(job.wait(show=True)), operator.itemgetter(1))[0:100]:
writer.writerow([word, count])Setzt man show=True, dann gibt Disco den aktuellen Stand auch gleich
im Konsolenfenster aus. Allerdings war das in meinem Fall keine so gute Idee,
da die Ausgabe nicht zu einem Ende kam, sondern immer im Kreis gelaufen ist.
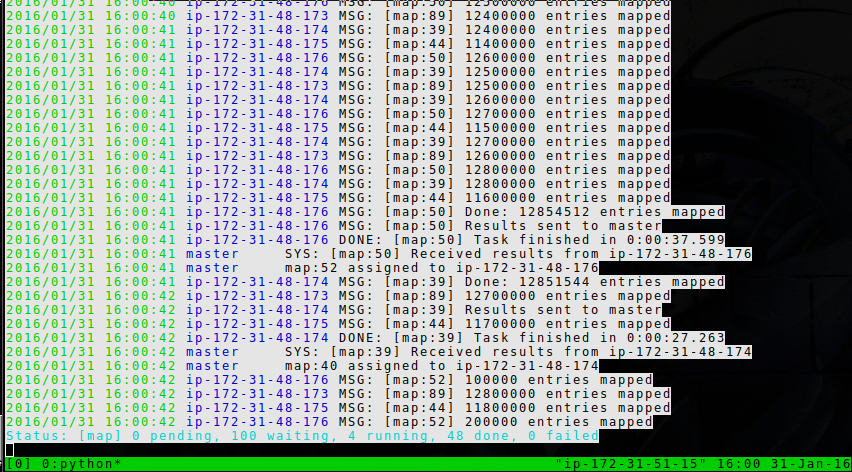
Wie man sieht, arbeiten tatsächlich mehrere Worker gleichzeitig an der Aufgabe, da die Aufgabe groß genug ist alle verfügbaren.
Die Rechenzeit für obiges Script betrug in meinem Fall beim ersten
Durchlauf 20 Minuten, beim zweiten 60 Minuten und beim letzten Durchlauf
dann mehrere Stunden (jeweils 5 Worker,
da ich den Master wegen des DDFS-Problems ebenfalls aktivieren musste). Ich
vermute, dass die Last im Rechenzentrum größer wurde, da in us-east
noch Morgen war, als ich die ersten Tests startete. Beim
letzten Durchlauf war es in den USA dann 14 Uhr.
Knoten on-the-fly als Worker hinzuzufügen scheint bei Disco nicht möglich zu
sein. Als ich merkte, dass die Berechnung im letzten Durchlauf so lange
dauern würde, startete ich einen neuen Slave, verteilte die SSH-Keys und das
.erlang.cookie und konnte ihn erfolgreich in den Cluster einfügen
(sichtbar durch eine schwarz hinterlegte Überschrift im Web-Interface), aber
es bleibt weiterhin bei fünf gleichzeitig laufenden Jobs und die Liste
current nodes hat sich nicht verändert.
Es kann jedoch auch sein, dass dies möglich wäre, wenn die Daten ebenfalls auf diesen neuen Slave verteilt wären (denn bei Hadoop und Disco führt Map-Reduce führt die Berechnung möglichst auf dem Knoten aus, wo auch die Daten liegen). Allerdings habe ich in der Dokumentation keinen Aufruf gefunden, mit dem man ein Rebalancing der Daten anstoßen könnte. Re-Replication wird automatisch gemacht, das scheint mir aber nur dann einzutreten, wenn Nodes ausfallen.
Eine Menge DNS-Requests
Auch als alle Rechner in derselben Availability Zone waren, war das Problem mit dem regional traffic nicht gelöst. Ich bin dem Problem auf den Grund gegangen und fand heraus, dass Disco ziemlich viel DNS-Anfragen stellt - pro Node mehrere pro Sekunde. DNS-Anfragen gehen in eine andere Availability Zone.
Als Gegenmaßnahme installieren wir uns dnsmasq auf dem Master. Da wir die
Ubuntu-Maschinen verwenden, müssen wir auch mit resolvconf umgehen. Außerdem
wollen wir diese Änderungen alle gleich bei der Einrichtung der Maschinen
automatisiert durchführen. Das Paket selbst müssen wir natürlich installieren:
apt-get -y install dnsmasqDie Hauptkonfiguration von dnsmasq kommt in /etc/dnsmasq.conf:
echo "resolv-file=/etc/resolv.dnsmasq.conf" >> /etc/dnsmasq.conf
echo "interface=eth0" >> /etc/dnsmasq.conf
echo "no-dhcp-interface=eth0" >> /etc/dnsmasq.conf
echo "expand-hosts" >> /etc/dnsmasq.conf
echo "domain=ec2.internal" >> /etc/dnsmasq.confDen AWS-Nameserver müssen wir in der /etc/resolv.dnsmasq.conf eintragen:
echo "nameserver 172.31.0.2" > /etc/resolv.dnsmasq.confUnd dann müssen noch die richtigen Einstellungen für resolvconf gesetzt
werden in /etc/resolvconf.conf:
echo "name_servers=127.0.0.1" > /etc/resolvconf.conf
echo "dnsmasq_conf=/etc/dnsmasq.conf" >> /etc/resolvconf.conf
echo "dnsmasq_resolv=/etc/resolv.dnsmasq.conf" >> /etc/resolvconf.confJetzt müssen diese Änderungen nur noch an den Slaves eintragen, damit
diese auch den Master als Nameserver verwenden. Da ich meine Probleme mit
resolvconf hatte, habe ich den Symlink einfach gelöscht und mir eine
good ol’ resolv.conf-Datei angelegt.
rm /etc/resolv.conf
echo "nameserver {MASTER_PRIVIP}" > /etc/resolv.conf
echo "search ec2.internal" >> /etc/resolv.confDie Master-IP wird vor dem Starten der Slaves in die User-Data der Slaves eingetragen.
slave_script = slave_script.replace('{MASTER_PRIVIP}',
master_info['PrivateIpAddress'])Nach diesen Anpassungen werden DNS-Requests nur noch etwa alle 30 Sekunden an den AWS-Nameserver durchgereicht, alle anderen beantwortet dnsmasq aus dem Cache.
Ubuntu-Repository-Server
Wie sich herausstellte, war auch danach mein Problem mit regional traffic nicht gelöst. Nach weiterem Debugging kam ich darauf, dass es an dem Standard-Ubuntu-Repository-Server lag. Dieser ist ebenfalls innerhalb des AWS-Netzwerks angesiedelt. Das bedeutet für mich natürlich bei jedem Installieren von Paketen Traffic in irgendeine Availability-Zone von AWS. Um dieses Problem - auch im Sinne der Ubuntu-Distributoren - sinnvoll zu lösen, habe ich letztlich die fertigen Master- und Slave-Distributionen als neue AMI gesichert und konnte dann direkt diese laden.
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.