Wer kennt wen über welche Ecken? Mit Wegematrizen!
Vor einiger Zeit hatte ich geschrieben, wie man Freundschaftsketten in sozialen Netzen mit einer üblichen relationalen Datenbank abbilden und ermitteln kann.
Durch die Grundbegriffe der Informatik- und Programmieren-Vorlesungen an der Universität stieß ich dabei auf eine neue Variante. Dabei verwenden wir Rekursion und Wegelängen.
Speicherung der Daten
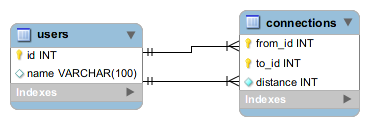
Wir starten wieder mit zwei Tabellen, einer für unsere Benutzer und einer für die Freundschaftsbeziehungen. Jedoch speichern wir in der zweiten nicht nur direkte Freundschaften, sondern auch Distanzen größerer Länge. Dabei geben wir allerdings immer nur die kürzeste Distanz zwischen zwei Personen an. Dazu führen wir eine neue Spalte distance ein.
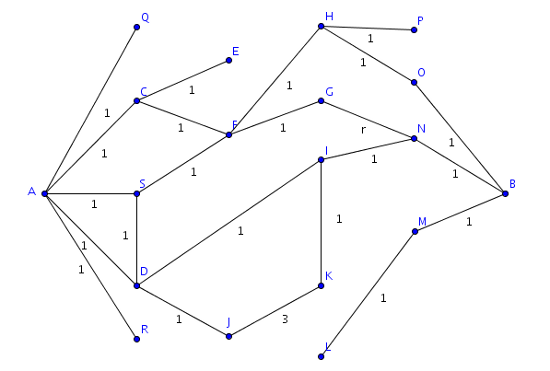
Stellen wir uns nun ein Gefüge aus sozialen Bekanntschaften vor.
Sehen wir uns die Speicherung innerhalb unserer relationalen Datenbank anhand einiger Beispiele an
--- users ---
id name
1 A
2 B
3 C
4 D
--- connections ---
from_id to_id distance
1 2 4
1 3 1
1 4 1
2 3 4
2 4 3
3 4 2
Da Freundschaftsbeziehungen ungerichtet sind, bilden wir jeweils nur eine Richtung ab (und zwar von der kleineren ID zur größeren). Es lässt sich leicht erkennen, dass in unserem kleinen Beispieldatensatz nur zwei Paare direkt befreundet sind, nämlich A-C und A-D. Die übrigen Paare sind über eine bestimmte Anzahl von Zwischenfreunden miteinander bekannt. Im Falle von C-D (3-4) gibt es einen gemeinsamen Freund, über den sich die beiden kennen (nämlich A).
Man kann sich nun fragen, ob diese Distanztabelle nicht viel zu groß würde, immerhin besitzen die meisten Personen mehrere Freunde und diese wiederum besitzen mehrere Freunde und so weiter. Ein Vorteil für uns ist aber, dass viele Menschen doch denselben Freundeskreis haben. Für menschliche soziale Gefüge ist diese Modellierung also durchaus möglich, denn die meisten Freundes-Freunde müssen wir gar nicht mehr eintragen, da wir schon eine direkte Freundschaft zu ihnen haben.
Nehmen wir ein reales Beispiel. Peter ist mit Thomas, Mark und Frank befreundet. Frank seinerseits ist mit Peter, Thomas und Anke befreundet. Den Weg von Peter über Frank zu Thomas müssen wir nicht extra speichern, denn wir kennen Thomas schon als direkten Freund von Peter.
Der Algorithmus
Der Algorithmus stammt nun aus der Vorlesung Programmieren und macht sich zunutze, dass alle Weglängen in unserer Tabelle bereits optimal sind. Haben wir also einen Pfad \(v_1 \rightarrow v_2 \rightarrow \ldots \rightarrow v_n\) der Länge k, dann muss \(v_2 \rightarrow \ldots \rightarrow v_n\) ein Pfad der Länge k-1 sein.
Nehmen wir uns zur Illustrierung ein Beispiel aus unserem obigen Graphen: Wir suchen die kürzeste Freundschaftskette zwischen A und H. Laut unserer Datenbank gibt es eine solche Verbindung, sie hat die Distanz 3. Das heißt aber gerade, dass alle Freunde, über die A H kennen kann, eine Distanz von 2 haben müssen.
Prüfen wir dies einmal nach. Laut Tabelle sind die Freunde von A: R, D, S, C und Q
Wir stellen eine Datenbankabfrage, ob es für diese eine Verbindung zu H mit der Länge 2 gibt. Dies ist nur für S und C der Fall. Von D zu H sind es 3 Schritte, von R und Q sogar 4.
Je nach Implementierung des Algorithmus können wir nun sowohl S als auch C untersuchen (bei Xing konnte man sich früher alternative Pfade anzeigen lassen) oder nur eines behalten. Da es für das Verständnis reicht, wollen wir nur S weiterverfolgen. Wir suchen nun also einen Freund von S, der zu H die Distanz 1 hat. S hat zwar viele Freunde, doch nur F hat zu H die Distanz 1. Damit haben wir unsere Freundschaftsverbindung bereits gefunden: A - S - F - H
Implementierung in Python
Eine Implementierung in Python könnte folgendermaßen aussehen:
def findPath(fro, to, length):
path = []
if fro == to:
return [to]
friends = getDirectFriends(fro)
for friend in friends:
if hasPath(friend, to, length-1):
return mergeLists([fro], findPath(friend, to, length-1))Wobei die Funktionen einen Pfad von fro nach to der Länge length finden soll. Dabei wurden folgende Hilfsmethoden verwendet:
- getDirectFriends(): Sucht alle direkten Freunde (Distanz 1) zur aktuellen Person heraus
- hasPath(): Prüft, ob zwischen zwei Personen ein Pfad bestimmter Länge existiert
- mergeLists(): Vereint zwei Listen zu einer einzigen
Die Hintergrundarbeit
Manch ein Leser mag sich jetzt fragen, woher denn die Zahlen in der Datenbank kommen. Diese müssen wir natürlich immer noch berechnen. Allerdings können wir dies nun im Hintergrund (entweder als Cronjob oder anhand einer Auftrags-Warteliste, sobald sich etwas im Graphen ändert) erledigen. Dort dürften die Operationen auch etwas länger dauern. Geschwindigkeit ist für uns vor allem bei der Abfrage wichtig, wenn wir darstellen wollen, wer wen kennt.
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.