Wer kennt wen über welche Ecken?
Viele Social-Networks binden einen Algorithmus zum Anzeigen der Bekanntschaftskette an, der bis zu einer bestimmten Anzahl von Ecken anzeigt über welche Freunde ich eine bestimmte Person kenne. Größere Plattformen werden für solche Probleme vermutlich ein geeigneteres Datenbankmodell, wie z.B. Graphen-Datenbanken, verwenden. Man kann es jedoch auch mit den verbreiteten Relationalen Datenbanken (RDBMS) umsetzen, wenn man eine kleine Feinheit beachtet.
Je mehr Ebenen man durchsuchen will, desto mehr Freundesfreunde sammeln sich natürlich auch an. Geht man davon aus, dass jede Person etwa 100 Kontakte hat (in Social Networks sind es üblicherweise mehr), kämen nach 6 Ebenen eine unüberschaubare Zahl von möglichen Verbindungen zusammen; rechnersich eine Billon.
Beide Personen als Startposition verwenden
Verwendet man jedoch beide Personen als einzelne Ausgangspunkte, bis man in der Mitte zu einem gemeinsamen Punkt gelangt, kommt man bei den gleichen 6 Ebenen zwar immer noch auf 1 Billion mögliche Wege, allerdings benötigt man hierfür viel kleinere Abfragen an die relationale Datenbank (kleinere Ergebnismengen und wenigere WHERE-Bedingungen). Dies liegt daran, dass anstatt von 6 Ebenen nun zweimal 3 Ebenen abgearbeitet werden.
Zwar ist der Geschwindigkeitsgewinn im Endprogramm kaum spürbar, da immer noch 1 Billion mögliche Verbindungen vorliegen, die Datenbank allerdings wird es euch danken, wenn sie nicht alle Freunde nach 5 Ebenen herausfinden muss, da hier schon eine ganze Menge Benutzer zusammenkommen. Genaue Zahlen kann ich leider nicht nennen, da mein Datensatz lediglich 500.000 Benutzer umfasst und viele Freundschaften ins Leere laufen (zu Personen, deren Freunde im kleinen Testdatensatz nicht mehr bekannt sind). Allerdings führen selbst diese Testdaten bei mir bereits zu 5000 Kontakten auf der 4. Ebene, die Abfrage der 5. Ebene dauert bereits zu lange.
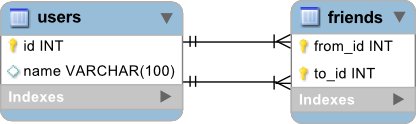
Die MySQL-Tabellen
Zur Darstellung von Benutzern und Bekanntschaften verwende ich zwei Tabellen. Eine enthält die einzelnen Benutzer, die andere alle gerichteten Verbindungen, d.h. es existieren für jede Freundschaft zwei Einträge: Einmal von Person A zu Person B und einmal von Person B zu Person A. Sollten tatsächlich alle Kontaktverbindungen gegenseitig sein, lohnt sich diese Darstellung nicht, da sie dann doppelt so viel Platz verbraucht.
Funktionsweise des Algorithmus
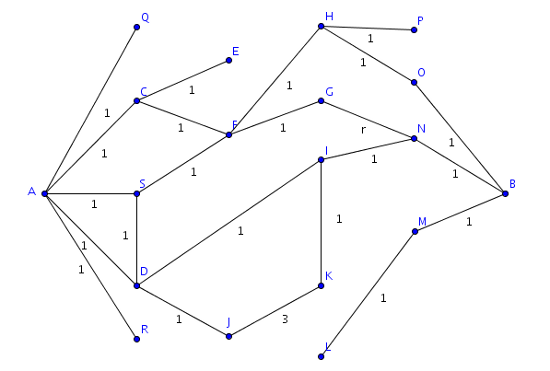 Um die kürzeste Verbindung zwischen zwei Personen zu finden, geht man nun einfach immer abwechselnd von Person A und von Person B einen Schritt weiter und prüft, ob in den inzwischen bekannten Listen bereits irgendwelche Überschneidungen anzutreffen sind. Im besten Fall würde solch eine Überschneidung bereits vor einem Datenbankzugriff (die Person selbst) oder nach dem ersten Zugriff von links (Person ist direkter Kontakt) zustande kommen.
Um die kürzeste Verbindung zwischen zwei Personen zu finden, geht man nun einfach immer abwechselnd von Person A und von Person B einen Schritt weiter und prüft, ob in den inzwischen bekannten Listen bereits irgendwelche Überschneidungen anzutreffen sind. Im besten Fall würde solch eine Überschneidung bereits vor einem Datenbankzugriff (die Person selbst) oder nach dem ersten Zugriff von links (Person ist direkter Kontakt) zustande kommen.
Der erste Schritt von links
Dazu setzt man zuerst einen Query „von links“ ab. Da wir später mit Mengen weiterarbeiten müssen, verwenden wir hier bereits das SQL-Keyword IN:
SELECT from_id, to_id FROM facebook_friends
WHERE from_id IN (A)Mit dem Ergebnis prüft man, ob Person B bereits in to_id enthalten ist. from_id wird zusätzlich ausgelesen, um eine Tabelle von gefundenen Personen und ihren Vorgängern für jeden Schritt erstellen zu können. Beim ersten Schritt wäre dies zwar noch ohne Datenbank möglich, da bekannt ist, dass alle Kontakte den Vorgänger A haben, beim zweiten Schritt gibt es allerdings schon viele verschiedene Vorgänger.
Der erste Schritt von rechts
Hat man nach dem Auslesen der direkten Kontakte von A noch keine Überschneidung mit B gefunden, geht man von B aus einen Schritt nach links, diesmal jedoch über die Spalte to_id, da B das Ziel des Pfades darstellt.
SELECT from_id, to_id FROM facebook_friends
WHERE to_id IN (B)Anschließend vergleicht man die beiden Ergebnismengen miteinander und sucht nach einem gleichen Wert. Sobald ein Wert in beiden Mengen vorhanden ist, hat man eine mögliche Verbindung (über die Person, die in beiden Mengen vorkommt) gefunden. Will man nur eine mögliche Verbindung anzeigen, kann man an diesem Punkt bereits abbrechen. Falls man alle kürzesten Wege gleich behandeln will, muss man die komplette Schnittmenge bilden.
Im obigen Beispiel würden die Mengen nun links Q, C, S, D, R und rechts O, N, M beinhalten. Somit ist noch keine Verbindung gefunden.
Der zweite Schritt von links
Sollte an diesem Punkt noch keine Schnittmenge vorhanden sein, führt man die Abfrage wieder von links her einen Schritt weiter. Diesmal verwendet man jedoch nicht die ID von A, sondern die IDs von allen Kontakten von A, welche man zuvor aus to_id ausgelesen hat:
SELECT from_id, to_id FROM facebook_friends
WHERE from_id IN (Q, C, S, D, R)Es wird wieder geprüft, ob eine Schnittmenge zu den bisherigen Mengen von rechts vorhanden ist. Falls ja, wird abgebrochen, falls nichts wird von rechts aus wieder ein Schritt getan. Dies geht solange weiter, bis:
- eine Verbindung gefunden wird
- es keine noch weiter distanzierten Kontakte gibt, oder
- man den Algorithmus abbricht, weil die Distanz zu groß wird
Das obige Beispiel wäre nach 4 Schritten gelöst, von jeder Seite aus zwei. Die Ergebnismenge nach zwei Schritten von links wäre E, F, D, I, J, die Ergebnismenge nach zwei Schritten von rechts H, G, I, L. Damit überschneiden sich die Mengen bei I. Benötigt man nur die minimale Distanz, kann man an diesem Punkt aufhören und die Länge ausgeben.
Ermittlung des Pfades
Falls man am Pfad selbst interessiert ist, muss man diesen noch zurückverfolgen. Dies kann man bewerkstelligen, indem man die Vorgänger für jeden Schritt in einem Key-Value-Speicher (Array in PHP, Dictionary in Python) ablegt. Damit muss man am Ende nur noch die einzelnen Schritte von der Mitte aus nach links und rechts verfolgen und kommt so auf den Gesamtpfad. In meinem Python-Skript sieht dies folgendermaßen aus:
path = []
# Speichern des mittleren Freundes
# Dieser ist der Zielpunkt bei diesem Algorithmus
path.append(friend)
leftCache.reverse()
rightCache.reverse()
# Den linken Cache für jede Ebene durchlaufen
for cache in leftCache:
path.insert(0, cache[path[0]])
# Den rechten Cache für jede Ebene durchlaufen
for cache in rightCache:
path.append(cache[path[len(path)-1]])
return pathDer Cache wird umgekehrt, da er in in von außen nach innen hin gespeichert wurde, der Algorithmus für den Pfad nun aber von innen nach außen zurückkehrt. Der Algorithmus fängt in der Mitte an und ermittelt zunächst den Vorgänger von I auf der linken Seite. Dieser ist im letzten Element von leftCache unter dem Index I gespeichert. Da ich zuvor für jedes Element nur den ersten gefunden Vorgänger gespeichert habe, wird lediglich Person D zurückgegeben. Beim Ermitteln des Vorgängers von D wird A zurückgegeben. Zwar ist auch S ein Vorgänger von D, allerdings wurde dieser Verbindung erst später gefunden und daher nicht mehr angefügt.
Jedes gefundene Element wird dann dem Pfad vorangestellt, da wir von rechts her ermitteln, den Pfad allerdings von links anzeigen wollen. Die Verarbeitung des rechten Caches läuft gleich ab, außer dass die Pfadelemente hier hinten angehängt werden, da der Weg von der Mitte nach außen auf dieser Seite bereits von rechts nach links weist.
Das Ergebnis des obigen Beispiels ist: A, D, I, N, B
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.