Load Balancing and Auto Scaling with Open Source HAProxy
When your application has more demand than can be handled by a single machine or when you want to safe-guard against failure or a single server, you might want to load balance it. There are different patterns to load balance an application, e.g. you can offload the heavy processing through a message queue, or you can redirect traffic directly to different servers. In this tutorial we will look at the latter.
On my job I’m currently working a lot with AWS, so I will first introduce the topic by showing how it works on AWS. Then we will have a look at the general problem and finally we will see an open source solution. In the end we will extend the load balancing to create an auto scaling system (partly in practice, partly in theory). My goal is to show you how you can achieve load balancing and auto scaling with open source software to avoid cloud vendor lock-in.
In my opinion, open source load balancing can be useful both for fully self-hosted as well as IaaS environments, whereas auto scaling might make more sense for IaaS environments. It doesn’t have to be AWS or Azure, though. For example, the German hosting provider Hetzner also has an API to manage VMs. I only see a use case for auto-scaling in self-hosting if you run multiple applications and your infrastructure is big enough to handle changing demand of said applications without addition or removal of physical servers.
Load Balancing and Auto Scaling at AWS
Before we dive into the software, let’s first have a look at AWS. In total we will look at three EC2 sub services:
- Target Groups
- Load Balancers
- Auto Scaling Groups
AWS EC2 provides both load balancing and auto scaling. Load balancing in EC2 works with Load Balancers and Target Groups. A target group is a group of VMs running the same service. A load balancer is the server that receives the original request and forwards it to one of the servers inside the target group. In fact a load balancer in AWS usually also consists of two servers (maybe even more, I’ve only seen two up to now). AWS hides these servers from you and only hands a DNS hostname to you. The DNS hostname resolves to the actual load balancer servers.
Now let’s imagine a user visiting your web service. You will probably have setup a CNAME or similar to forward from your public domain to the load balancing hostname. So the user’s request will be forwarded to the load balancer. One of the load balancer servers will receive the request. It will then forward the request to any of the servers that are currently active inside the attached target group. The selected server will process the request, respond to the load balancer which will in turn send the response to the user.
A target group periodically performs health checks on each server belonging to the target group. If health checks fail the server will be marked as down. The load balancer can use this information to stop forwarding requests to this server. Health checks will continue to be run on this server and once it is considered to be OK again, it will be marked as up in the target group and load balancers can continue forwarding requests.
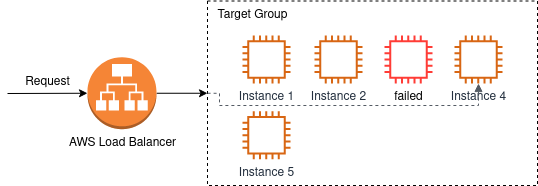
That’s load balancing in AWS without auto scaling. To add auto scaling, we have to use Auto Scaling Groups. An auto scaling group is a definition for auto scaling behaviour for a service. It defines:
- what kind of servers should be started (i.e. which VM specs and which base image to use for the VM)
- what’s the limit for minimum and maximum number of servers (you probably don’t want to wake up and see 0 or 1000 servers running by accident)
- which metrics to use to decide if more or less servers are required
- whether a failed load balancer health check should lead to replacement of the VM
Auto scaling will track a metric and when the metric is over a threshold it will start more servers and add them to the target group. Load balancers will then have one more target to forward requests to and hopefully the metrics should be in acceptable ranges again. If the metric below a threshold servers can be removed from the target group to save cost.
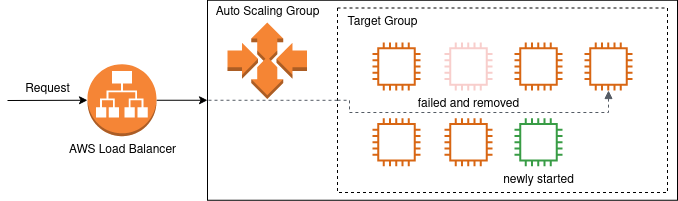
Removing servers from a target group introduces a new state. We already saw that servers in a target group can be up and down. When a server is removed from the target group, it goes into state draining. The draining state signals that there might still be requests running on this server, but no new requests should be sent to this server by the load balancer. To my knowledge on AWS the target remains in the draining state for a fixed amount of time. After the draining period the server will be removed from the target group no matter whether there are still active connections. At the same time the auto scaling group is also free to terminate the server.
Load Balancing Algorithms
How does the load balancer determine the target to which it should forward a request?
There are many different algorithms for this decision. Not all of them are supported by all software products. We will quickly have a look at the most common ones in this section.
In a Round Robin load balancing scheme each server gets one request and then the load balancer switches to the next server. When the load balancer has reached the last server, it will start from the beginning again. This scheme is usually supported by all software. Round Robin can be extended to the Weighted Round Robin which can handle sets of servers of different size. Imagine you have one server with 4 cores and one server with 16 cores. The server with 16 cores can probably handle more requests in the same time, so it would make sense to forward more requests to the more powerful server. This is what Weighted Round Robin does.
Protocols with long-lasting connections can use the Least Connections scheme. In this load balancing scheme the server with the least number of open connections receives the request. AWS calls this load balancing scheme Least Outstanding Requests.
Two other common methods are Source IP Hash and URL Hash. In both cases an input value (IP address or URL) is used to determine the target server. The load balancer calculates the hash of the IP address or URL and then takes the modulo of it to get the index of the server to which it should route the request. In case of Source IP Hash this has the advantage that requests from the same IP address will always go to the same server. With URL Hash requests to the same URL will always be processed by the same server. Both schemes can be helpful to re-use cached data, Source IP Hash can also be useful when the user’s session storage on the backend is not global.
Of course, it’s also possible to forward requests to a random server.
Open Source Load Balancing
Now that we have seen how load balancing and auto scaling are handled in AWS, let’s see how we can do it with open source software.
Preparation with Vagrant
To test load balancing we will launch a few VMs with Vagrant. Each VM will simulate one web server. I chose Vagrant over Qemu, because it allows us to specify the IP address of VMs from the outside. I assume that libvirt might also be capable of this, but in my opinion a Vagrantfile is a bit simpler to understand in a blog post than a libvirt XML definition.
So, create the following Vagrantfile.
Vagrant.configure("2") do |config|
config.vm.define "web1" do |web|
web.vm.box = "ubuntu/focal64"
web.vm.network "private_network", ip: "192.168.50.101"
web.vm.provision "shell", path: "install_web.sh", args: "web1"
end
config.vm.define "web2" do |web|
web.vm.box = "ubuntu/focal64"
web.vm.network "private_network", ip: "192.168.50.102"
web.vm.provision "shell", path: "install_web.sh", args: "web2"
end
config.vm.define "web3" do |web|
web.vm.box = "ubuntu/focal64"
web.vm.network "private_network", ip: "192.168.50.103"
web.vm.provision "shell", path: "install_web.sh", args: "web3"
end
end
This vagrant file will use a provisioning script called install_web.sh
which must be in the same folder. The script installs nginx with a simple
HTML file containing the index of the server. This will allow us to see
load balancing in action when we access the site.
apt-get install -y nginx
echo "Hello $1!" > /var/www/index.html
cat <<CONF > /etc/nginx/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
server {
listen 80;
server_name localhost;
location / {
root /var/www;
index index.html index.htm;
}
}
}
CONF
systemctl restart nginx
The above definition gives us a few VMs running web servers, each one serving a simple page with the server’s name.
Load Balancing with HAProxy
HAProxy provides a lot of features for load balancing. Many people also use nginx for load balancing, but in this tutorial we will be using HAProxy, because it gives us an overview over the current health checks which can also be exported to CSV. This will allow us to act on health checks and shutdown machines that are not healthy, anymore.
The HAProxy blog gives a good introduction to the configuration file format.
global
maxconn 20000
log 127.0.0.1 local0
user haproxy
chroot /usr/share/haproxy
pidfile /run/haproxy.pid
daemon
stats socket /run/haproxy.sock mode 666
stats timeout 60s
frontend main
bind :5000
mode http
log global
option httplog
option dontlognull
option http_proxy
option forwardfor except 127.0.0.0/8
timeout client 30s
default_backend app
frontend stats
bind *:8404
mode http
stats enable
stats uri /stats
stats refresh 10s
timeout client 30s
backend app
mode http
balance roundrobin
timeout connect 5s
timeout server 30s
timeout queue 30s
server web1 192.168.50.101:80 check
server web2 192.168.50.102:80 check
server web3 192.168.50.103:80 check
With this file we configure the load balancer to balance traffic on
port 5000 across the servers defined in the backend app. All servers will
be checked for their health status.
HAProxy provides two ways to get access to health checks: the socket interface and the web page. For this tutorial I enabled both. The socket interface is best for programmatic access, while the web page is nice for getting an overview over the information that’s available. Both methods have an admin mode to change the HAProxy configuration, but in this configuration the admin mode is not enabled.
We are setting the mode of the socket file to 666 to allow standard users
to use the socket. That way, we won’t have to run our auto scaling script
as root.
When you have created the previous few files, start all the vagrant servers and HAProxy with something similar to (depending on your service manager):
vagrant up
systemctl start haproxy
If you visit http://localhost:5000 now and refresh the page a few times, you
should see messages from different web servers. You can also go to
http://localhost:8404/stats to view the HAProxy stats page.
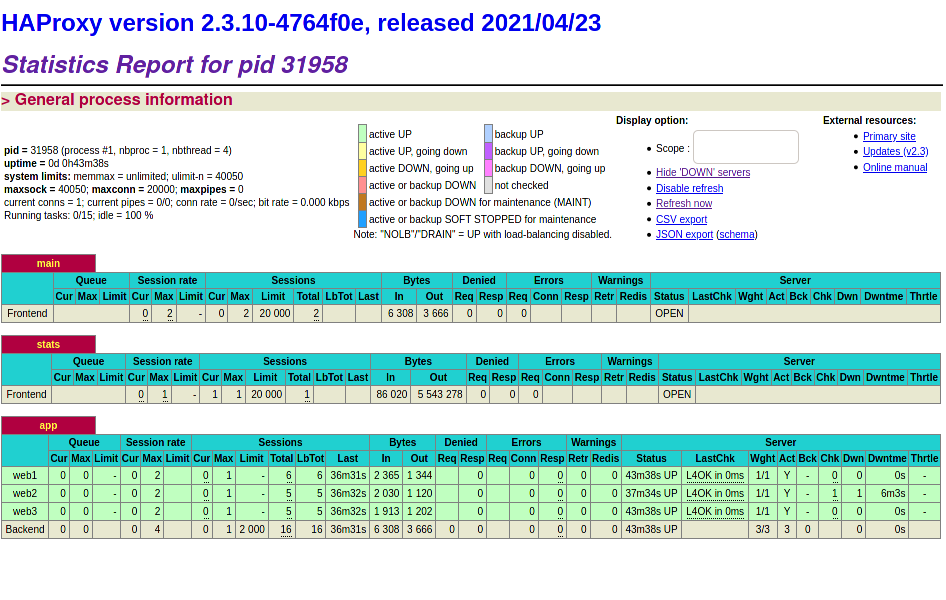
Let’s shutdown one of the web servers with vagrant destroy web2. HAProxy
will detect that this server is no longer available and mark it as down. It
will take a few seconds until the server is really marked down. During this
period it’s still possible that your request gets forwarded to the dead server
and will timeout.
The exact timings of health checks
can be configured
with the keyword inter (interval between checks) and fail (number of failed
tests, before server gets flagged unavailable).
There’s also the fastinter
and downinter keywords to set different intervals in transitioning phases.
E.g. this would allow you to perform regular health checks every 10 seconds,
but after the first failed health check you poll every 2 seconds until the
server is considered down or up again.
Auto Healing
Now let’s add functionality similar to AWS auto scaling to this setup. This means we want to:
- remove unhealthy instances and start a new instance
- add and remove instances depending on a metric value
We will use HAProxy, because it gives us access to the live health situation of instances. For this proof-of-contept we will continue to use Vagrant, in a production environment you would probably use whatever API your IaaS provider offers.
A script will periodically check the health stats from HAProxy. When it detects a failed instance, it will take down this instance and start a fresh one. For this proof-of-concept we will just re-start the failed Vagrant VM. Otherwise, we’d have to generate a new Vagrantfile and a new HAProxy configuration file with the updated IP address. Feel free to implement it yourself as an exercise.
#!/usr/bin/env bash
while true; do
echo "Checking health stats"
echo "show stat" | socat unix-connect:/run/haproxy.sock stdio | \
sed '1s/^# //; /^$/d' > haproxy_stats.csv
down_servers=$(sqlite3 haproxy_stats.sqlite <<SQL
DROP TABLE IF EXISTS haproxy;
.mode csv
.import haproxy_stats.csv haproxy
SELECT svname FROM haproxy WHERE type = 2 AND status = 'DOWN';
SQL
)
for server in $down_servers; do
# Take down the unhealthy server
vagrant destroy -f $server
# Create a fresh server
# For PoC simply re-start the same VM
vagrant up $server
done
sleep 10
done
In this script we fetch the current stats from the unix socket. We remove the leading hash from the header line, delete empty lines and then import everything into SQLite. SQLite allows us to easily filter the rows for all rows that are of type server (type 2) and are in status down.
We then iterate over these servers and take them down. For simplicity we do
not define new VMs in the Vagrantfile, but instead just restart the same VM.
Auto Scaling
Extending this to scale servers up and down based on a metric is (in theory) quite easy. It seems a bit of work to me to do in a short shell script, so I will only describe the theory. It should be straightforward to implement with e.g. Python, though.
Let’s say we have a metric file with the number of desired servers inside. This
file will be periodically checked by a Python script, or it could even be
monitored by something like inotify. The service will then compare the
current number of active servers to the desired number of servers. There
are three cases:
- desired and actual number of servers match: nothing has to be done
- there are too many servers: remove a few servers
- there are too few servers: start new servers and add them to load balancing
If there are too many servers, we will have to remove some of them from HAProxy. This
means that the service will have to write a new HAProxy configuration file
with a few servers set to disabled and then reload HAProxy. It should not
shutdown the servers immediately, because there might still be active connections
being processed. This corresponds to the AWS mode draining that we saw in
the beginning.
Our Python service then has to monitor the number of active connections on the
server that it wants to shutdown. This can be retrieved from the HAProxy stats
socket. Once all connections are closed, the server can be fully removed
from the HAProxy configuration and can be shutdown.
If more servers are required, the service has to boot new servers. Now there are two possible ways to continue. Since HAProxy already includes health monitoring of servers, the servers can be added to HAProxy immediately. Requests will only be routed to these servers once the server is up. If you choose this way make sure to select a reasonable health check method in HAProxy. The standard TCP health check might not work depending on your exact web application startup behaviour. You also want to make sure that these servers are not taken down again due to their unhealthy status (in AWS this is called grace period for new instances).
Alternatively, the Python service could boot the servers and monitor them on its own. Once the servers are ready, it can add them to the HAProxy configuration file and reload HAProxy.
Conclusion
In this blog post we have seen that conceptually it is quite simple to create an auto scaling load balancer with open source software and thereby avoid vendor lock-in with a specific cloud hosting provider. If we use HAProxy for load balancing instead of relying on e.g. EC2 load balancers, we can take our application and host it on AWS, Azure, Hetzner or any other IaaS provider with a management API. If we don’t need auto scaling we could even use our own bare metal servers (technically you can of course also scale VMs on your own bare metal, but I don’t see much sense in it, since the servers are running nonetheless).
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.