Eine Einführung in Amazon Dynamo
In der Welt der alternativen Datenbanken haben sich auch einige Systeme von namhaften Unternehmen hervorgetan. Ein relativ einfach verständliches, aber dennoch interessant System dabei ist Amazon Dynamo. Dynamo ist ein Key-Value-Store von Amazon, welcher nicht als OpenSource vertrieben wird, sondern auf den eigenen Servern eingesetzt und zum Mieten angeboten wird.
Verteilung von Servern in einem Ring
Amazon Dynamo setzt dabei vor allem auf eine extrem hohe Geschwindigkeit, welche auch im von Amazon veröffentlichten Paper mehrmals beworben wird. Diese wird vor allem durch eine starke Verteilung auf verschiedene Server erreicht. Das bedeutet, dass ein Amazon Dynamo System üblicherweise aus mehreren Servern besteht. Diese werden in einem Ring angeordnet, wobei jeder Server für bestimmte Wertebereiche der Schlüssel zuständig ist. Dieser Schlüssel wird dabei über eine Hash-Funktion ermittelt. Da bei Amazon Dynamo neue Knoten vollkommen willkürlich im Ring angeordnet (und somit ggfs. unterschiedliche Spannbreiten an Wertebereichen entstehen würden), setzt Dynamo auf virtuelle Server, sodass mehrere virtuelle Server für einen einzigen (wenig belasteten) Server zuständig sein können.
Datensicherung
Zur Datensicherung gibt es eine bestimmte Anzahl an Nachfolgern, die ebenfalls für die Speicherung von Daten zuständig sind.
Nehmen wir als Beispiel den Ring “A-B-C-D” mit vier virtuellen Servern. Würde man nun den Sicherungswert so setzen, dass jeweils zwei Server eine Information speichern, dann würde B Daten sichern, die A als erste Instanz speichern müsste, C solche, die eigentlich auf B landen, und D solche Daten, die auf C gespeichert werden sollen.
Wir können dies in folgender Grafik veranschaulichen:
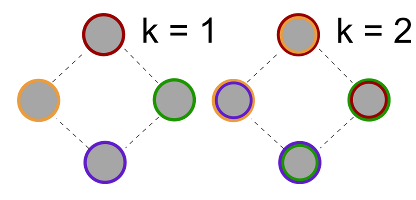
Links sieht man, wie die Kopienverteilung aussieht, wenn jeder Server nur seine eigenen Informationen speichert. Rechts speichert jeder Server auch noch die Kopien seines Vorgängers. Das heißt, der ehemals grüne Server speichert nun auch die roten Daten seines Vorgängers.
Versionierung von Daten
Der wahrscheinlich kritischste Punkt bei einer verteilten Speicherung mit sogenannter eventual consistency (d.h. die Daten müssen nicht auf allen Servern gleichzeitig geschrieben werden, dadurch haben manche Server die neuen, manche noch die alten Daten) ist die Synchronisierung.
Ein Beispiel für so eine Problematik gibt amazon selbst mit dem Einkaufswagen an. Angenommen ein Benutzer legt ein Produkt in seinen Einkaufswagen. Nun gibt es ein Serverproblem und der bisherige Server ist nicht mehr erreichbar. Der Benutzer erhält also einen alten Einkaufswagen von einem Ersatzserver und liegt hier vielleicht noch ein Produkt ab. Falls am Ende der Einkaufstour das Serverproblem behoben ist, soll der Benutzer trotzdem wieder alle Produkte in seinem Wagen sehen (und nicht nur die, die der 2. Server kennt).
Dazu setzt Amazon Dynamo auf sogenannte Vector Clocks. Dies sind Vektoren von Tupeln mit den Anzahlen an Änderungen, die jeder Server vorgenommen hat. Angenommen wir haben folgende Aktionsfolge auf einem Eintrag
- Server1 ändert den Eintrag
- Server1 ändert den Eintrag erneut
- Server2 ändert den Eintrag
- Server3 ändert den Eintrag
- Server1 ändert den Eintrag erneut
so führt dies zu folgender Folge an Änderungen der Vektoruhr:
[(Server1, 1)][(Server1, 2), (Server2, 1)][(Server1, 2), (Server2, 1), (Server3, 1)][(Server1, 2)][(Server1, 3)]
Durch diese Struktur kann erkannt werden, ob zwei Ereignisse einander beeinflusst haben oder ob sie nebenläufig sind. Gerade die Nebenläufigkeit ist zur Auflösung von Konflikten notwendig, denn man muss erkennen, wo zwei Versionen eventuell nicht aufeinander aufbauen. Sofern zwei Einträge aufeinander aufbauen, ist die Sache klar: Der ältere Eintrag wird nicht mehr benötigt und muss nicht mehr ausgeliefert werden.
Nehmen wir aber an, es gibt zwei nebenläufige Versionen. Diese beiden Versionen werden dann an den Klienten ausgeliefert, welcher für das Zusammenführen zuständig ist. Nach der erfolgreichen Zusammenführung gibt er dem Server einen neuen Schreibauftrag und dieser führt die Vektoruhren so zusammen, dass erkenntlich ist, dass beide vorherigen Vektoruhren in den neuen Eintrag eingflossen sind.
Dies sieht dann z.B. so aus:
- Auf einem Server liegt
[(Server1, 2), (Server2, 1)] - Auf einem zweiten Server liegt
[(Server1, 2), (Server3, 1)] - Angenommen Server2 koordiniert den näcchsten Vorgang und erhält den Auftrag, eine zusammengeführte Version zu speichern, dann sieht die neue Vektoruhr so aus:
[(Server1, 2), (Server2, 2), (Server3, 1)]
Im letzten Schritt wurde Server2 noch um eins hochgezählt, weil nur so erkennbar ist, dass der neue Eintrag wirklich neuer ist als die beiden anderen (um dies zu erkennen, muss mindestens ein Eintrag echt größer sein als die vorherhigen).
Statistik
Laut Amazons Paper gibt es übrigens bei 99,94% der Anfragen nur eine eindeutige Version (und somit keine Zusammenführung). Bei den meisten Anfragen mit mehr als einer Version lag dies nicht an Ausfällen im System, sondern an gleichzeitigen Anfragen durch Robots. Allerdings geht Amazon nicht weiter auf die Bedeutung der Robots ein.
Hinzufügen und Entfernen von Knoten
Knoten können flexibel an irgendeinen Punkt im Ring eingehängt werden. Dem Server werden zufällige Hash-Werte-Bereiche aus dem Ring zugeteilt, für die dieser von nun an zuständig ist. Da bisher andere Server diese Bereiche bedient haben, ist nun ein Transfer der aktuellen Daten notwendig. Dazu bitten die bisherigen Server beim neuen Server um Akzeptanz und nach Rückmeldung werden die Daten übertragen. Sobald alle Daten übertragen sind und alle Server im Ring über die Änderung Bescheid wissen, kann der Server dem Ring hinzugefügt werden und ist von nun an für alle Übertragungen zuständig.
Das Entfernen von Servern geschieht auf die gleiche Weise, nur dass nun Daten von verlassenden Server zu einem anderen Server transferiert werden müssen. Sobald alle Daten erfolgreich auf die anderen Server übertragen wurden und alle Server im Ring über diese Änderung informiert wurden, kann der Server den Ring verlassen.
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.