Wie entwickle ich meine eigene Suchmaschine: URLs und Links sammeln
Sehr häufig kommt die Frage auf, wie man sich seine eigene Suchmaschine programmiert. Von Anfängern wird dabei häufig die Komplexität solch eines Vorhabens verkannt, doch es gibt ein paar Grundlagen, an die man sich halten kann. In einer mehrteiligen Reihe will ich beleuchten, um welche es sich dabei handelt.
Wo kriege ich die Seiten für meine Suchmaschine her?
In einem Programmierer-Forum bin ich kürzlich auf die Frage gestoßen, wie man denn an die Webseiten komme, um sie in dem Index der Suchmaschine zu speichern. Der Fragesteller dachte dabei zuerst an eine automatische Generierung von Domainnamen, die er dann prüfen wollte. Dies kann sicherlich für sehr einfache Domainnamen funktionieren, ob es sich jedoch lohnt, ist eine andere Frage. Geht man nach der Theorie des PageRanks, welcher Seiten als wichtiger einstuft, auf die öfter verlinkt wird, ist so ein Vorgehen nutzlos: Wenn db.de wirklich eine wichtige Domain ist, wird man sie anhand der Links früh genug finden, unwichtigere zweistellige Domains vielleicht erst sehr spät.
Genau dieses Vorgehen wird heutzutage eigentlich auch immer eingesetzt. Ein sogenannter Crawler oder Spider – den es als erstes auf dem Weg zur eigenen Suchmaschine zu entwickeln gilt – besucht eine Seite, analysiert die dortigen Links und besucht die Links (um diese auch wieder zu analysieren und weitere Links zu besuchen). Aus all diesen Seiten, die man findet, wird dann der Index aufgebaut.
Vorsicht: Abgetrennte Teilnetze
Ein Problem an dieser Methode ist tatsächlich die Auswahl der Startseite(n), da dies einen starken Einfluss auf den Crawling-Vorgang haben kann. Wählt man wenig vernetzte Seiten, könnte es passieren, dass man am Ende nur einen Teil des Webs findet. Um dies zu umgehen, bietet sich eventuell durchaus eine Durchforstung mit einigen automatisch generierten URLs an. So könnte man z.B. die Domains aus einem Wörterbuch erstellen und durchsuchen.
Vorsicht: Endloslinks
Aufpassen muss man aber auch, dass man nicht zu viele Links indiziert. Die meisten Crawler setzen deshalb bei einer einzelnen Domain eine maximale Tiefe ab dem Einstieg ein: Nach etwa 6 Links ist dann Schluss und er Crawler bricht ab. Dies schützt vor Endloslinks wie sie z.B. bei dynamisch generierten Kalendern vorkommen können (wenn man endlos lange auf “nächste Woche” klicken kann).
Für jede neu gefundene Seite muss man sich also die Tiefe notieren, welche dann Tiefe der aktuellen Seite+1 beträgt. Bei bereits gefundenen Seiten entfällt dieser Schritt, sofern die bereits ermittelte Tiefe geringer ist als die neue Tiefe. Bei einer Tiefensuche kann es dazu kommen, dass man eine Seite zuerst mit Tiefe 5 einstuft, später aber noch sieht, dass ein Link von einer anderen Seite nur zur Tiefe 3 führen würde. In diesem Fall sollte man die Tiefe aktualisieren.
Dabei sollte man jedoch auch noch darauf achten, die Tiefe von der Startseite aus zu messen (http://www.example.com/), da man ansonsten wieder in Endlosverlinkungen landen kann (z.B. wenn man von einer anderen Domain endlos viele Einstiegspunkte in den Endloskalender und von hier wieder zurück zur anderen Domain findet).
Höflichtkeit beachten (politeness policy)
Jeder gutartige Web-Crawler sollte höflich sein. Der englische Begriff politeness wird dabei tatsächlich als Fachbegriff für Crawler verwendet und bedeutet, dass ein Crawler den Server nicht übermäßig beansprucht. In einer Datei namens robots.txt kann ein Webseitenbetreiber mit der Direktive Crawl-delay festlegen, wie oft ein Crawler die Domain besuchen soll (in Sekunden). Ein guter Crawler sollte sich daran halten und in der Zwischenzeit nur Seiten von anderen Domains abrufen.
Dieser Schritt gilt insbesondere für das Abgrasen von Links, da diese meist direkt weiter zur gleichen Domain führen, aber auch für den folgenden Punkt – das Wiederbesuchen von bereits gefundenen Seiten.
Welche Seite wie häufig besuchen?
Da das Web dynamisch ist und sich Inhalte immer mal wieder ändern, muss man sich überlegen, wie oft man auf Webseiten nach Änderungen suchen will. Das einfachste Konzept wäre, bei jeder Seite nach Ablauf einer bestimmten Zeit nach Änderungen zu sehen. Dies hat sich jedoch als ineffizient herausgestellt, da manche Seiten sich häufiger ändern und andere seltener.
Nehmen wir als Beispiel nur mal die Startseite einer Zeitung und die Seite eines einzelnen Artikels. Während die Seite des Artikels sich wahrscheinlich kaum mehr ändert und eine Aktualisierung jede Woche (auch noch nach 1 Jahr) sinnlos wäre, ist eine Aktualisierung jede Woche für die Startseite viel zu wenig.
Deshalb muss man die Aktualisierungszeit dynamisch anpassen. Hier bietet es sich an, für jede Seite mit einem bestimmten Wert zu starten und diesen dann nach oben oder unten zu verschieben, wenn man weiß, ob eine Änderung vorhanden war. Dazu könnte man zum beispiel eine tanh-Funktion verwenden (Tangens hyperbolicus). Verschiebt man diese um 0,5 nach oben und drückt sie um den Faktor 0,5, erhält man immer einen Wert zwischen 0 und 1, welchen man dann als minimale und maximale Besuchshäufigkeit definieren könnte (z.B. alle 5 Minuten und alle 12 Monate).
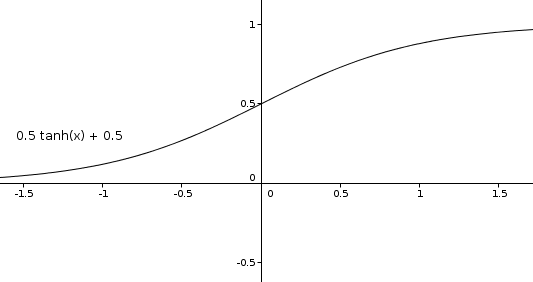 Diese Funktion hat die Stärke, dass sie sich in der Mitte sehr stark verändert und zum Ende hin nur noch langsam. Das heißt Anfangsfehler werden sehr schnell korrigiert, aber bei bereits sehr gefestigten Strukturen wird nichts zerstört, nur weil die Seite sich einmal nicht verändert hat. Um überhaupt Änderungen bei schon lange existierenden Seiten zuzulassen, sollte man natürlich trotzdem einen maximalen und minimalen Wert auf der x-Achse definieren (z.B. -10 und +10).
Diese Funktion hat die Stärke, dass sie sich in der Mitte sehr stark verändert und zum Ende hin nur noch langsam. Das heißt Anfangsfehler werden sehr schnell korrigiert, aber bei bereits sehr gefestigten Strukturen wird nichts zerstört, nur weil die Seite sich einmal nicht verändert hat. Um überhaupt Änderungen bei schon lange existierenden Seiten zuzulassen, sollte man natürlich trotzdem einen maximalen und minimalen Wert auf der x-Achse definieren (z.B. -10 und +10).
Speicherung der Daten
Man muss sich natürlich auch überlegen, wie die erlangten Daten gespeichert werden sollen. Je nachdem, was man vom Crawler gleichzeitig alles speichern lässt (nur Links oder Links und HTML-Quelltext), muss man hierzu verschiedene Speicherformen betrachten.
Für die Speicherung der Links bietet sich eine Graph-Datenbank an. Diese ist darauf optimiert Vernetzungen von einzelnen Knoten abzubilden und genau das stellt die Linkstruktur des Internets dar.
Zur Durchsuchung von Text sind diese nun allerdings überhaupt nicht geeignet. Nun ist die Frage, was man mit dem vielleicht bereits erlangten HTML-Quelltext anstellen will. Üblicherweise dient dieser selbst noch nicht als Suchgrundlage, da er auch die HTML-Tags enthält, nach welchen Benutzer meistens nicht suchen möchten. Wenn ich in einer Suchmaschine h2 eingebe, möchte ich keine Ergebnisse, die irgendwo auf der Seite eine Überschrift verwenden, sondern solche, die Überschriften in ihrem Artikel erklären. Deshalb stellen die HTML-Quelltexte meist nur eine Rohform dar, die später noch überarbeitet werden muss. Daher würde ich in solch einem Fall zu einer einfachen Speicherform greifen: der dokumentenorientierten Datenbank. Sie bietet gegenüber den relationalen Datenbanken den Vorteil, dass sie einfacher auf mehrere Server verteilt werden kann und daher eine Lastverteilung besser möglich ist (ein wichtiger Faktor, wenn man sehr viele Crawler gleichzeitig laufen lässt, und damit sehr viele Datenbankzugriffe gleichzeitig hat).
Ausblick
Mit diesem Wissen kann man sich nun bereits einen ersten kleinen Web-Crawler schreiben, der von einigen Startseiten aus das Internet nach weiteren Links durchsucht. Damit kann man seinen Suchmaschinen-Index befüllen lassen, allerdings noch keine Ergebnisse anzeigen. Je nach Zweck der Suchmaschine können die nächsten Schritte auch ganz unterschiedlich ausfallen: Will z.B. man eher Texte durchsuchen lassen oder eine Datenbank bereitstellen? Will man das ganze Netz durchsuchen oder nur bestimmte Themen?
Außerdem gibt es auch bei der Crawler-Programmierung noch einige Dinge zu beachten, welche ich im nächsten Teil dieser Serie beleuchten werde.
I do not maintain a comments section. If you have any questions or comments regarding my posts, please do not hesitate to send me an e-mail to blog@stefan-koch.name.